Améliorer la disponibilité des services
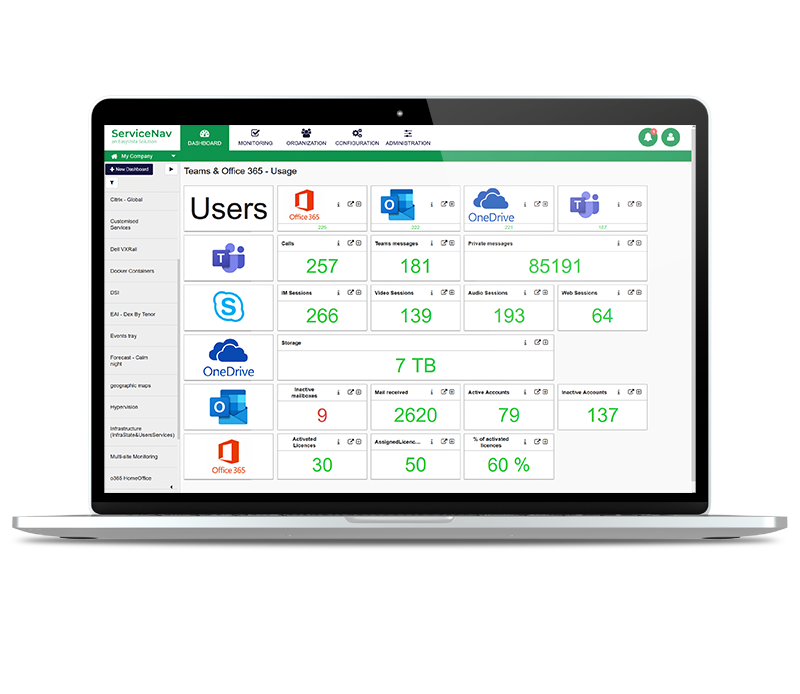
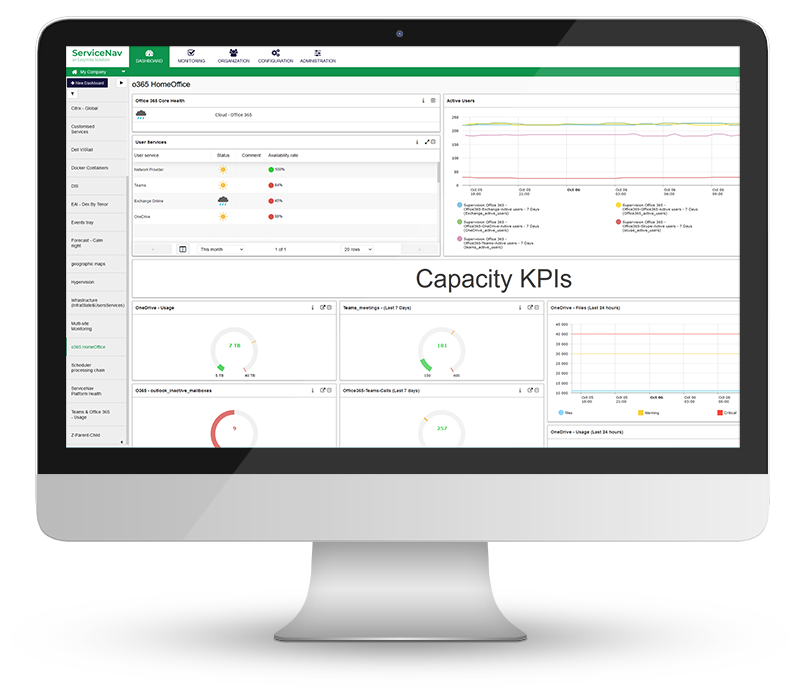
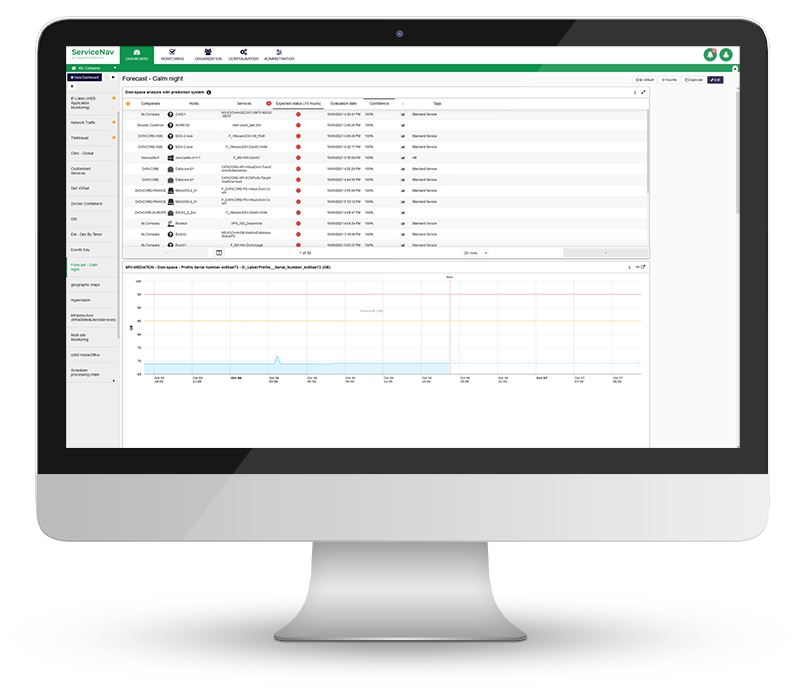
Monitorez, en temps réel, votre infrastructure informatique, votre réseau, votre IoT, le cloud et vos applications. Gardez vos actifs supervisés à jour. Configurez des seuils d’alertes dynamiques basés sur des recommandations de notre technologie d’IA et diminuez le nombre de faux positifs de 30 %. Enfin, ne manquez aucune alerte grâce aux notifications multicanales et aux tableaux de bord.